
Data Drift in LLMs—Causes, Challenges, and Strategies
- Chapter 1: AI Infrastructure
- Chapter 2: Large Language Model (LLMs)
- Chapter 3: Vector Embedding
- Chapter 4: Vector Databases
- Chapter 5: Retrieval-Augmented Generation (RAG)
- Chapter 6: LLM Hallucination
- Chapter 7: Prompt Engineering vs. Fine-Tuning
- Chapter 8: Model Tuning—Key Techniques and Alternatives
- Chapter 9: Prompt Tuning vs. Fine-Tuning
- Chapter 10: Data Drift
- Chapter 11: LLM Security
- Chapter 12: LLMOps
Data drift, also known as concept drift or data shift, refers to the phenomenon where the distribution of input data used to train a machine learning model changes over time, leading to degradation in the model’s performance on new data. While this has been an issue plaguing machine learning models for decades, the explosion of popularity of LLMs means that the adverse effects of data drift have a far more significant impact on software end users. It is more important than ever to understand what data drift is, its implications, and how to reduce its effects in production.
Summary of key concepts
| Concept | Description |
|---|---|
| Understanding drift in LLMs | Data drift refers to the changes in the statistical properties of LLM input data. Over time, the training data becomes less representative of the data the model encounters in real-world usage. |
| Causes of drift |
|
| Implications of drift |
|
| Strategies for managing drift |
|
| Challenges in addressing drift | While many challenges exist in addressing drift, computational costs and data privacy are particularly concerning. |
Understanding data drift in LLMs
In large language models (LLMs), data drift refers to the change in the text distribution of initial model training data. Over time, the training data becomes less representative of the data the model encounters in real-world usage. As a result, the LLM’s performance degrades, leading to less coherent, accurate, or relevant outputs.
Concept drift is about changes in the underlying relationship between the inputs (data) and the correct outputs over time. This phenomenon occurs when the decision boundary between classes shifts due to underlying changes in the data generation process.
Model drift refers to the scenario where a model’s performance degrades over time, not because the model has changed but because of changes in the environment in which it operates. Even if an LLM remains static after deployment, the world it was trained to understand does not. New topics of interest, events, or changes in public discourse can lead to situations where the model’s predictions become less accurate or relevant.
One example of this would be COVID-19. Had LLMs been ubiquitous during that time, a dramatic shift in the vocabulary used due to this novel disease likely led to LLMs being more likely to hallucinate and create misinformation, as there was little to no information about the disease before March 2020.
Causes of data drift
We give some common causes of data drift in LLMs below.
Social and cultural factors
First, cultural and societal changes can significantly affect language use over time, which can cause drift. Language continuously changes due to various factors, such as
- Demographic shifts
- Technological advancements
- Political movements
- Social norms.
The changes may result in the emergence of new words, phrases, and slang terms that were not present during the LLM model’s training phase. Additionally, existing words and phrases might change their meanings or connotations based on cultural context.
For instance, LLMs trained to do sentiment analysis may struggle to analyze modern-day texts containing newly emerged expressions or sarcasm, resulting in incorrect classification or prediction.
Powering data engineering automation for AI and ML applications
-

Enhance LLM models like GPT and LaMDA with your own data -
Connect to any vector database like Pinecone -
Build retrieval-augmented generation (RAG) pipelines with no code
Domain-specific updates
Domain-specific updates and the introduction of new terminologies can lead to significant data drift, particularly in specialized fields like medicine, technology, finance, and science. New discoveries, regulations, and changing circumstances require updated vocabularies and concepts to describe them adequately.
For instance, domain-specific LLMs in medicine must be continually retrained with up-to-date clinical records and research publications to maintain accurate diagnoses and treatment recommendations. Similarly, LLMs specializing in finance need regular updating to reflect changing economic conditions and market dynamics.
Adversarial attacks
Adversarial attacks and user behavior can influence model outputs and cause data drift if the LLM model has a learning feedback mechanism and attacks are pervasive. Adversarial attacks intentionally manipulate inputs designed to mislead models or exploit their vulnerabilities. In particular, malicious actors may attempt to subvert a system’s integrity or functionality by:
- Introducing noisy or misleading inputs
- Generating adversarial examples that differ slightly from original inputs but substantially alter the model’s output.
Such actions can introduce bias and inconsistencies in the LLM algorithms, causing drift.
User behavior patterns
User behavior patterns can also contribute to data drift, especially if users modify how they interact with the system or generate inputs differently than anticipated during the initial design and development stages.
For example, users might employ unconventional spellings, grammar, or syntax while communicating with generative AI models, rendering the pre-trained models incapable of understanding or correctly interpreting the altered linguistic cues.
Implications of data drift
LLMs can be negatively impacted in several different ways due to data drift, including by the following:
Accuracy loss
The most direct consequence of drift is the decrease in prediction accuracy. An LLM trained on historical data might fail to capture current trends or emerging topics, leading to irrelevant or incorrect responses. For instance, consider a chatbot designed to answer questions related to COVID-19 prevention measures. If the guidelines change significantly, the bot could continue providing outdated information as its training data does not include these updates. As a result, users would receive misleading answers, affecting both user experience and overall trust in the system.
Inconsistency
This relates specifically to a change in the relationship between inputs and outputs. Let’s say that an LLM has been fine-tuned on customer reviews to classify them as positive or negative feedback. Due to changing consumer preferences, expectations, or product features, favorable attributes today might differ from those considered important during initial model development. Such shifts lead to erroneous predictions and compromise the model’s ability to deliver value consistently.
Safety concerns
Incorrect interpretations can have severe consequences in some high-stakes applications, such as healthcare, finance, or legal domains. A sudden change in regulations or market dynamics might render previously accurate decisions unsafe or illegal.
Strategies for managing data drift in LLMs
Monitoring and updating LLMs is crucial to ensure they remain safe and effective in evolving contexts.
#1 Continuous learning and training
You can periodically retrain your models using fresh data to adapt to changing patterns and relationships. There are two approaches
- Online learning— the model incrementally updates its weights as each new example becomes available. This can be particularly useful when dealing with large streaming datasets.
- Batch learning—retraining the model from a previous checkpoint* using batches of more recent data.
*Unlike traditional machine learning models, training an LLM from scratch would be cost and resource-prohibitive. Thus, starting from a pre-trained off-the-shelf checkpoint makes more sense here.
Deploying active learning strategies allows targeted label acquisition, focusing on regions exhibiting the highest uncertainty, thus amplifying returns per label procured.
Unlock the Power of Data Integration. Nexla's Interactive Demo. No Email Required!
#2 Monitoring and evaluation
You can consistently track and compare LLM performance metrics such as perplexity, accuracy, precision, recall, F1 score, and others (depending on the task the LLM is trained to do) against predefined thresholds. You could even use a second LLM to grade the outputs. If any metric drops significantly, this could indicate possible data drift.
In addition, comparing key features between current and historical data distributions may reveal drifts due to a decline in the model’s abilities. Various statistical tests, such as the Kolmogorov–Smirnov or Mann–Whitney U-test, can help determine whether two samples come from the same distribution. While Kolmogorov-Smirnov focuses on the maximum distance between the empirical distribution functions of two samples, Mann-Whitney specifically tests differences in medians or distributions’ central tendencies.
Employing alert systems upon observing significant deviations enables prompt intervention before adverse impacts materialize.
An example of monitoring and evaluation of data drift with AWS (Source)
#3 Human-in-the-loop
While automation is vital in scaling LLM applications, humans still hold essential responsibilities throughout the model lifecycle. Human oversight, through mechanisms known collectively as “human-in-the-loop,” provides valuable guidance during model development, deployment, maintenance, and improvement. Experts continuously supervise model outputs and examine predictions and confidence levels associated with those forecasts. For example, human experts can:
- Validate complex decisions
- Make judgments under ambiguity
- Address novel situations outside the scope of existing training data
- Facilitate collaboration among teams working with LLMs.
When encountering suspicious results, human experts actively intervene. For example, they provide labeled instances and corrections, steer the model towards better decision boundaries, and ensure ethical considerations are met.
![]()
Human in the loop process (Source)
#4 Data augmentation
Addressing data drift often entails expanding training datasets with synthetic or curated data points to augment diversity. Data augmentation techniques include adding noise, cropping, rotating images, altering textual input, generating adversarial examples, or leveraging other generative models to create new samples (e.g., pseudo-labeling and model distillation). It also includes fine-tuning previously learned representations utilizing newer chunks of data. When facing dramatic shifts in distribution, complete model retraining may become necessary.
Organizations must strategically plan their data collection efforts, seeking diverse sources and timely representation to bolster re-training initiatives.
Data augmentation process (Source)
{kind=link}
#5 Dynamic adaptation
Dynamic adaptation is continuous retraining with real-time data. Dynamic adaptation tactics collectively endow AI models with self-regulatory abilities. The process works as follows.
- Online learning algorithms integrate with stream processing frameworks to assimilate incoming knowledge progressively.
- Transfer learning architectures extract foundational feature hierarchies from sizable initial datasets.
- They then fine-tune parts of the model while engaging in live environments.
You can choose to either fine-tune the last layer or the last few layers (since these are the ones where the model specifically learns how to do a task). You can also tune the self-attention layers in line with LoRA and QLoRA, which find that training these can result in similar performance to training the whole model. Some workflows just train embeddings associated with the prompt (in line with the prompt tuning training method). This results in agile systems that are well-equipped to handle contextually varying conditions.
Meta-learning schemes (for example, using few-shot examples related to the new data) facilitate the rapid assimilation of new concepts. Reinforcement learning algorithms like RLHF (reinforcement learning from human feedback) and DPO (direct preference optimization) further optimize model responses via exploratory-exploitative tradeoffs, striking optimal balances between immediate rewards and long-term value accruals.
RLHF
RLHF allows an agent to learn how to make decisions by interacting with its environment and receiving rewards or penalties for its actions. In this situation, the agent is the language model learning how to adjust its outputs to match what humans are looking for. Rewards correspond to the human satisfaction of the model’s outputs. For example, an upvote for a language model’s content would be a positive reward, whereas a downvote for its output would be a negative reward. Since not all content will have a reward associated with it, we can train a reward model on any models with human feedback to label the data that doesn’t have a reward. You can then use it to optimize the LLM agent to create outputs that align better with human preferences.
DPO
DPO simplifies the RLHF process somewhat. It takes the positive reward data and trains the model to increase the probability of generating those positive outputs. It also decreases the likelihood that utterances with negative rewards are outputted.
Challenges in addressing drift
While there are many challenges in addressing drift, two are very important to address when working with LLMs: computational and data collection costs and privacy and data security.
Computational and data collection costs
Training large language models can take considerable time and computing power, particularly as the model’s size increases. Additionally, obtaining high-quality labeled data to train and update the model is a non-trivial task that requires substantial effort and expense.
Managing the storage and processing requirements of the ever-growing volumes of data needed for retraining is also challenging. This may require organizations to invest in high-performance computing clusters or cloud services to manage the demands placed on their systems by continuous model updates. Storage requirements can also be a problem for the models themselves.
Investments can add up quickly, so organizations must carefully consider the potential benefits and ROI of implementing LLMs before committing to significant resource expenditures.
Privacy and data security
Collecting and using new data for model training poses significant privacy and security risks. Preventing unauthorized access or misuse requires organizations to prioritize data governance, encryption, and secure transfer protocols. Ensuring compliance with data protection regulations like GDPR or CCPA requires additional resources and expertise.
In addition to external threats, internal issues can arise during data collection and preprocessing, such as biased datasets leading to unfair or discriminatory outcomes. Ensuring fairness and avoiding bias in LLMs requires careful consideration of how data is gathered, cleaned, and used throughout the development cycle. Organizations must incorporate diverse perspectives and avoid perpetuating harmful stereotypes or historical imbalances in language representation.
Tools for LLM data drift management
Avoiding problems like data drift requires organizations to develop AI infrastructure that supports continuous model monitoring and re-training. For example,
LangSmith is an all-in-one developer platform for every step of the LLM application lifecycle. It is designed to track the inner workings of LLMs and AI agents within your product. The debugging tools can troubleshoot agent loops, slow chains, and other response issues. LangSmith also provides visual feedback on accuracy metrics and can send real-time alerts by monitoring conversations.
Giskard AI is an upcoming platform for LLM monitoring and testing. It can automatically detect performance issues and generate evaluation reports. You can use it to unify your AI testing practices and use standard methodologies for optimal model deployment.
Beyond the above, LLM development requires implementing robust data management systems that support high-volume, high-velocity data processing without buckling. The infrastructure must support LLM embedding, enabling the seamless integration of the LLM into existing software architectures.
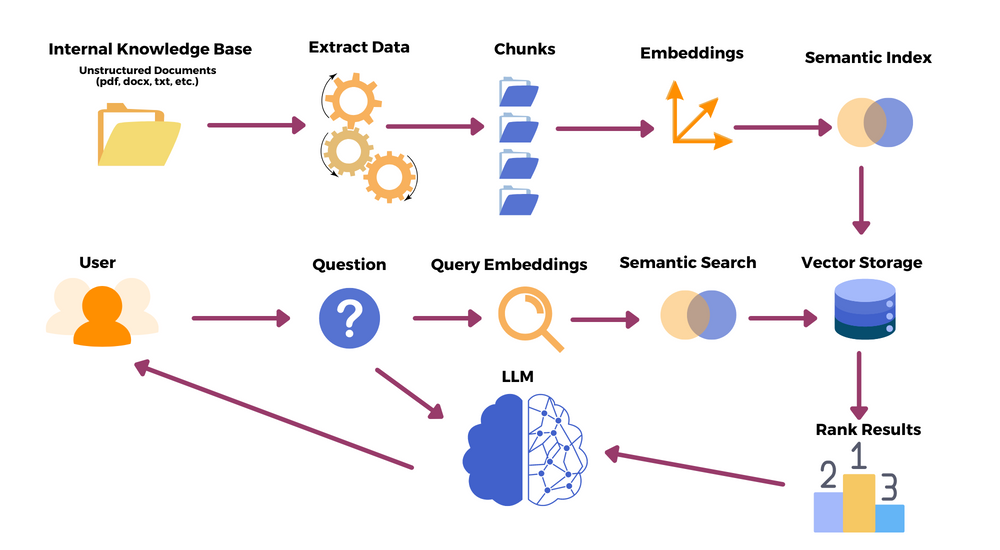
Nexla is a data integration platform that automates data engineering for your LLM operations. In particular, Nexla enables monitoring, evaluation, human-in-the-loop, data augmentation, and re-training for AI application development. You can connect any data source to a vector database so that data flows continuously in either direction. An intuitive UI allows non-technical users to share their datasets for fine-tuning LLMs or augmenting their data sets.
Discover the Transformative Impact of Data Integration on GenAI
Conclusion
Data drift can be a significant challenge when training and deploying LLMs. Cultural and societal changes, domain knowledge updates, and adversarial attacks can all set off a process that leads to LLMs becoming less helpful in their responses and potentially leading to safety concerns.
While various strategies for managing data drift exist, they all require intelligent monitoring and data lineage tools. A data integration platform like Nexla can support your LLM operationalization efforts by enhancing management. You can integrate any data source with your LLM training pipelines to reduce and manage drift more efficiently.