Document & Multimodal Integration
Turn Unstructured Data Into Agent-Ready Pipelines
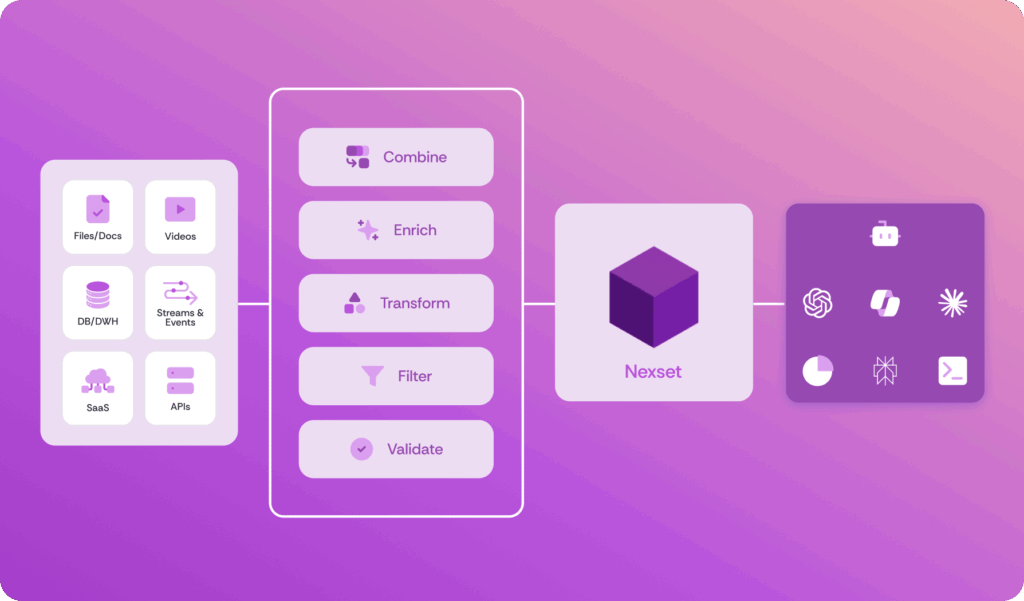
Nexla ingests documents, PDFs, emails, images, audio, and video – any unstructured or multimodal source and transforms them into governed Nexsets your AI agents and data pipelines can use immediately. No custom scripting required.