
GenAI Apps from Concept to Production: Powered by NVIDIA, Scaled & Simplified by Nexla
Taking a Retrieval-Augmented Generation (RAG) solution from demo to full-scale production is a long and…
Turn any source into AI-ready data, and deliver more accurate, enterprise-grade agents and assistants using the latest in agentic multi-LLM RAG, all without coding.
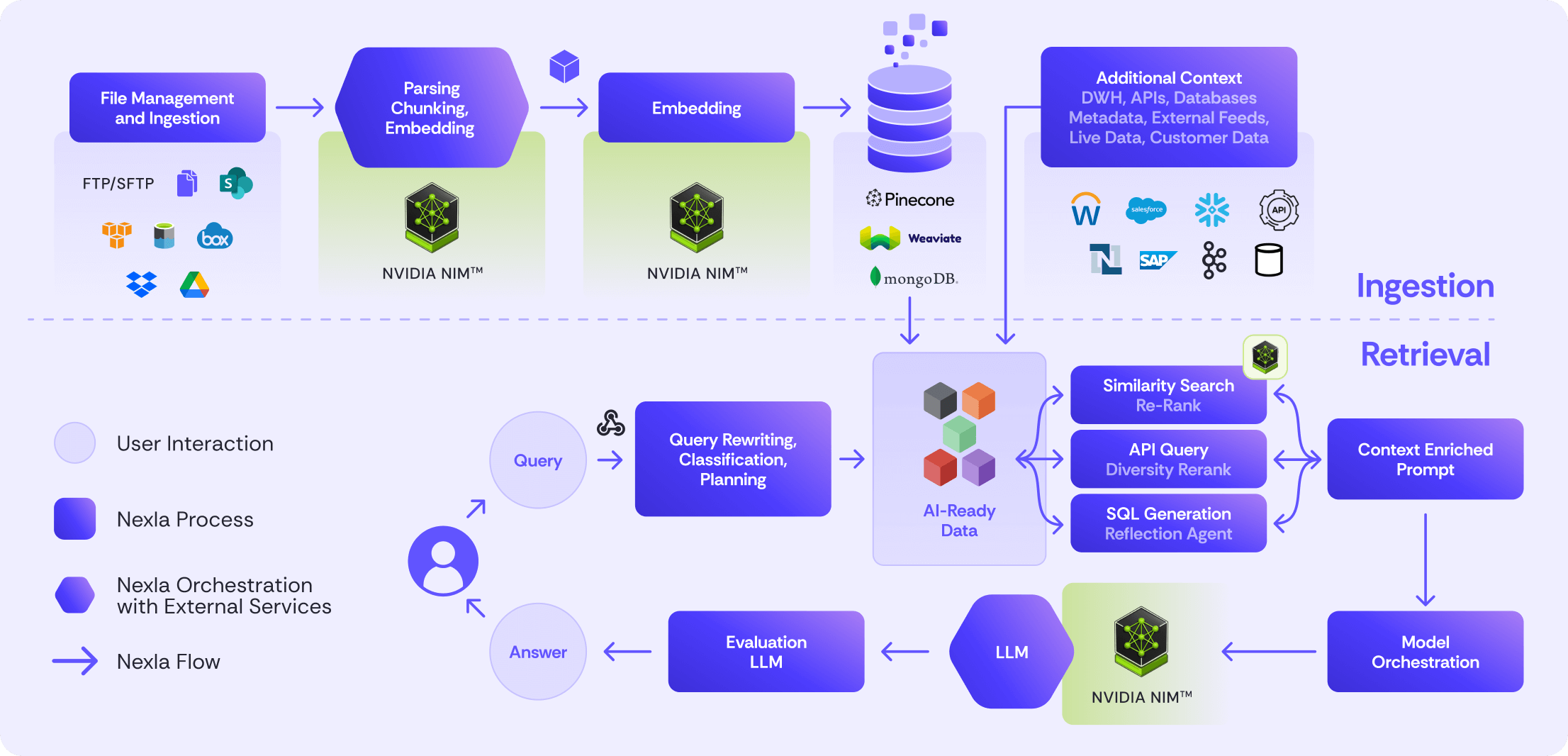

Get AI-ready data from 100s of different systems including documents, saas applications, using ELT/ETL, R-ETL, API integration, (S)FTP, streaming and more. Use advanced chunking to prepare documents and unstructured data. Load your vector database of choice and keep it up to date at any scale

Leverage the latest in agentic Retrieval Augmented Generation (RAG) – including query rewriting, agentic retrieval, re-ranking, multi-LLM usage, grading, and model orchestration – without having to code. Compose everything you need for integration and RAG together.

Nexla Orchestrated Versatile Agents (NOVA) is an agentic interface for composing pipelines using natural language (e.g. English) within the Nexla UI, built on Nexla’s agentic AI framework. You can use NOVA, no-code UI configuration, and pro-code mode interchangeably.

Unlike other vendors, Nexla doesn’t just retrieve context from one source. Nexla’s agentic retrieval uses AI to find any relevant data across vector databases and data products. More relevant data leads to more accurate results.

Nexla supports over 20 LLMs out of the box and makes it easy to add others. Evaluate multiple LLMs side-by-side. Then use the best LLM and other technologies to achieve the best results on quality, performance, and cost.

Nexla’s partnership with NVIDIA brings NIM support that accelerates parsing, inferencing, re-ranking, embedding, and SQL generation across integration and RAG.
Access any unstructured data using connectors for any document stores – including Sharepoint, SFTP, S3, Dropbox, Box, Google Drive and more – and use built-in agentic chunking to deliver AI-ready data.
Orchestrate across Nexla’s built-in PDF parser and advanced parsers from external providers including AWS Textract, Tesseract OCR, and Unstructured.
Nexla’s agentic chunking preserves semantic structure by identifying key sections, headings, and relationships using domain-specific chunking strategies. It balances LLMs and deterministic rules-based processing to achieve the best quality, price, and performance with linear scale.
Enhance your final outcomes with metadata infused embedding generation for powerful citations and data freshness management.
Embed data into the vector database of your choice without coding including Pinecone, Weaviate, and MongoDB with new connectors delivered under 24 hours.
Choose the best embedding algorithm for data from OpenAI, Cohere, NIMs, Voyage, and more, or add your own embedding algorithm in minutes.
Use built-in reranking or any 3rd party reranker to identify the best context for each query with the option to leverage NIM gpu acceleration.
Leverage built-in LLM result evaluation to help prevent hallucinations, or build test cases.
Evaluate and use the best models for each project. Choose from prebuilt connectors to over 20 models, or easily integrate to new models, including ones you run privately. Compare models side-by-side to help choose the best model based on quality, cost, and performance. Then use the best model and other technologies for each project in production.
Control all access to data via data products to encrypt or remove sensitive data and prevent data leaks. Leverage service key-based access ensures RAG flow can only access allowed data based on permissions.
Implement integration and RAG to support agents and assistants, and embed Nexla into your products via Nexla’s APIs to manage Nexla and invoke pipelines.

Nexla’s AI-powered integration and AI framework lets you build end-to-end integration and RAG without coding by using the NOVA chatbot or the Nexla UI to configure Nexsets, transforms, and flows.

Nexla’s converged integration – which provides fast access to any unstructured or structured data – and its composable RAG with agentic chunking, retrieval, and multi-LLM support all result in higher quality LLM outcomes and fewer hallucinations.

Rock solid security against prompt hacking built on strict user level access controls.

Composable design with ability to include Python gives our users the ability to tap into the latest advancements without dependency.
Taking a Retrieval-Augmented Generation (RAG) solution from demo to full-scale production is a long and…
Retrieval-augmented generation (RAG) represents an innovative approach to artificial intelligence (AI) that significantly improves how…
Have you encountered a situation where an LLM might not be giving you your expected…
Large language models (LLMs) are AI implementations that generate text. They are trained on terabytes…
Enterprise AI refers to the application of artificial intelligence to enhance business operations within large…
From GenAI prototypes to production: the contributions of integration engineers in model management, vector pipelines, RAG workflows, GPT quality control, & LLM governance.