
Data Integration Techniques—the Past, Present, and Future
- Chapter 1: Data Integration Techniques
- Chapter 2: ETL vs. ELT
- Chapter 3: Data Integration Tools
- Chapter 4: ETL Tools
- Chapter 5: API Data Integration
- Chapter 6: Data Synchronization
- Chapter 7: Data Integration Platform
- Chapter 8: Data Integration Process
- Chapter 9: Data Lineage Tools
- Chapter 10: ETL vs. ELT
Data integration is critical to modern data engineering, especially in AI and machine learning applications. As organizations increasingly rely on LLM (Large Language Models), ML (Machine Learning) training, and Retrieval-Augmented Generation (RAG) workflows, they require large volumes of both structured and unstructured data. Data integration challenges grow as data volumes and processing speed requirements rise.
You can observe the evolution of data integration techniques over four distinct generations. Initially, data integration involved traditional Extract, Transform, and Load (ETL) processes. API-based integration tools emerged to overcome the rigidness of ETL, allowing data to flow across applications. As cloud warehouses grew in prominence, teams adopted the ELT approach, using the cloud’s power to handle raw data before transforming it. Today, fourth-generation data integration tools unify operational and analytical use cases and support seamless data preparation for AI model training.
This guide explains various data integration techniques, from traditional methods like ETL to modern approaches such as data fabric and data mesh, which have become essential for handling complex AI and ML data pipelines.
Summary of key data integration techniques
| Concept | Description |
|---|---|
| ETL | Extract, Transform, Load – traditional data integration process. |
| Reverse ETL | Moving data from a data warehouse back to business applications. |
| Data integration via API | Integrating data using application programming interfaces. |
| ELT | Extract, Load, Transform – transforms data within the data store. |
| Data streaming (CDC) | Real-time data processing using Change Data Capture. |
| Data fabric | Data fabric creates a unified data layer across environments. Allows users to query and access data from multiple heterogeneous sources as a single source. |
| Data mesh | Data mesh decentralizes data ownership across teams, allowing them to manage data autonomously. |
| Data orchestration | Automatically manages, coordinates, and schedules data processes across various systems. |
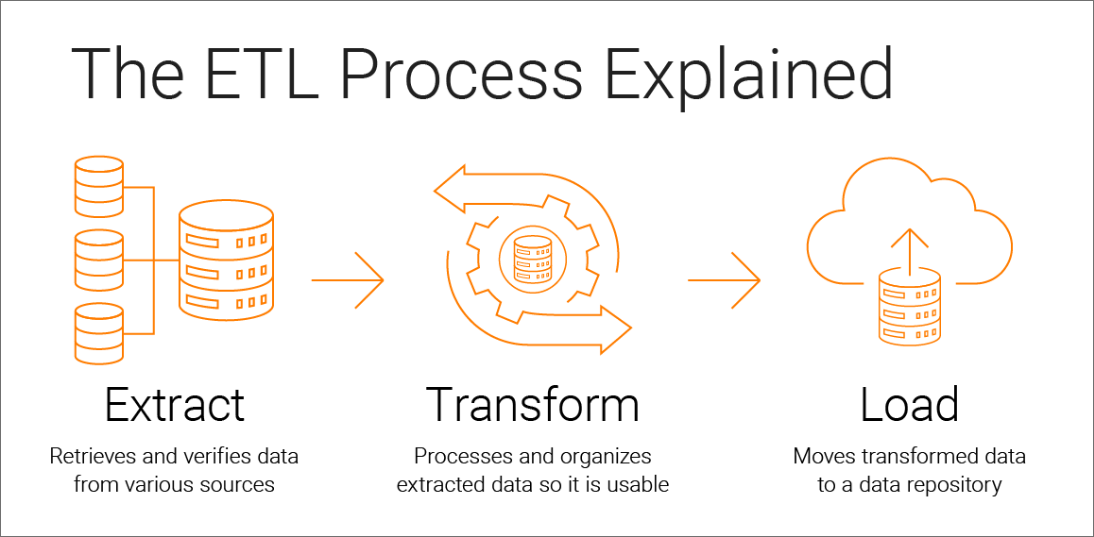
ETL (Extract, Transform, Load)

The ETL Process (source)
{kind=link}
In the early days of data engineering, many organizations faced the challenge of gathering information from disparate systems and making sense of it for analytics. This is where ETL came in. ETL stands for Extract, Transform, and Load, and it became the backbone of traditional data integration. Companies would use ETL to extract data from various source systems, transform it to meet their reporting needs and load it into centralized data warehouses. Though powerful, ETL’s batch-oriented approach required upfront transformations that could slow things down when data volumes grew.
In ETL, you extract data from various source systems, such as databases, cloud services, APIs, or flat files. Depending on the use case, this extraction can be done in batches or in real-time.
Once extracted, data moves to the transformation stage, where it is cleaned and formatted to meet destination system requirements. This step involves various transformations, such as filtering, aggregating, enriching, or joining data from multiple sources.
Finally, the transformed data is loaded into the destination system, typically a data warehouse or data lake. This loading can be done incrementally, meaning only new or updated data is loaded or done in bulk, depending on the organization’s needs.
For example, a retail company extracts sales data from multiple stores, transforms it to calculate daily sales totals, and loads the aggregated data into a central data warehouse for analysis.
Enterprise integration platform
for AI-ready data
-
Accelerate integrations with pre-built, configurable, and customizable connectors -
Deploy production-grade analytics and generative AI applications on a single platform -
Monitor data quality with automated lineage to alert on data failures and errors
Reverse ETL
As businesses became more data-driven, simply storing data in a warehouse wasn’t enough. Organizations needed ways to operationalize that data, pushing insights back into day-to-day tools like CRM systems and marketing platforms. Enter Reverse ETL, which moves data from a data warehouse or lake back into operational systems, such as CRM, marketing platforms, or other business applications.
In the Reverse ETL process, data is extracted from the data warehouse, transformed to fit the schema and requirements, and then loaded into the target operational system.
For example, a company uses reverse ETL to push customer segmentation data from a data warehouse into a CRM system so the sales team can target specific customer groups more effectively. Reverse ETL can also be applied to more advanced business use cases, such as sending enriched customer data back into marketing automation platforms from a data warehouse. This enables businesses to launch highly personalized campaigns that leverage AI-driven insights. Marketing teams can run more targeted, data-driven campaigns, improving engagement and conversion rates.
Application integration via API
API Integration Example (source)
As organizations outgrew the limitations of ETL, they began looking for more flexible ways to connect their data sources. API-based integration emerged as a game-changer, allowing systems to exchange data in real-time. By creating direct links between applications, APIs allowed businesses to respond to data as it flows rather than waiting for the next ETL batch cycle.
API data integration is commonly used in web and microservices architectures, where different services must interact. For example, smart home devices might use APIs to send real-time data to a central cloud service, where the data is processed and used to control the devices remotely.
How API integration works
In API-based integration, a client application sends a request to the server via an API, and the server processes the request and sends back a response. APIs allow applications to exchange data in various formats, such as JSON, XML, or plain text. This data can be anything from user information, transactional data, or real-time analytics.
APIs vary in their architecture and the protocols they implement. For example, REST APIs are stateless and work with standard HTTP methods (GET, POST, PUT, DELETE) known for their simplicity, scalability, and performance. GraphQL is a query language for APIs that allows clients to request specific data from the server. REST may use multiple endpoints to retrieve related data, but GraphQL enables clients to get all the necessary data in a single request. It reduces the amount of data transferred and improves performance.
API-first approaches have become essential for integrating real-time AI models, including GenAI. REST APIs, in particular, are widely used to build scalable, stateless connections between AI models and data sources to ensure AI models are constantly updated with the latest data for real-time processing, personalization, and decision-making. This approach is vital for companies building responsive, AI-enabled applications requiring continuous data flows from multiple systems.
Unlock the Power of Data Integration. Nexla's Interactive Demo. No Email Required!
ELT (Extract, Load, Transform)
As data volumes grew, many teams found that transforming data before loading it into storage could lead to delays and bottlenecks. Organizations began shifting towards the ELT process to overcome this.
After extraction, the raw, untransformed data is loaded directly into the destination system, typically a cloud data warehouse or data lake. Once the data is loaded, transformations are performed within the destination system using SQL queries, data transformation tools, or built-in functions provided by the platform.
ELT offers greater flexibility and speed by utilizing the cloud’s massive processing power. It is more efficient to leverage the scalability of modern data storage solutions like Snowflake, Google BigQuery, and Amazon Redshift than to handle complex transformations of large data volumes.
For example, a financial services company might use ELT to load transaction data into a data warehouse and then transform it to generate financial reports.
| Difference | ETL | ELT |
|---|---|---|
| Order of operations | Data is transformed before loading, | Data is loaded before the transformation. |
| Scalability | May cause bottlenecks and cost inefficiencies at scale as transformations require a separate data processing solution | Takes advantage of the scalability and processing power of cloud data warehouses and lakes. |
| Flexibility | Less flexible. | More flexible as raw data is available in its entirety within the destination system. |
| Performance | Less performant at scale. | Enables faster and more efficient data processing, especially with large datasets. |
Table summarizing ETL vs. ELT
Data streaming and CDC
Change Data Capture – CDC (source)
Modern applications like fraud detection, stock trading, personalized customer experiences, and IoT device monitoring require up-to-the-minute analysis of continuous, real-time data streams. Change Data Capture (CDC) is a specific data streaming approach that tracks and captures changes (inserts, updates, deletes) in a source system and streams those changes to a destination system. Data streaming and CDC enable organizations to react instantly to data as it is generated rather than relying on periodic batch processing.
How CDC works
Source database or application changes include new records (inserts), updates to existing records, and deletions. Different methods are used to detect changes. For example:
- Log-based CDC reads the database’s transaction log to capture changes. It is highly efficient and minimizes the impact on the source system.
- Trigger-based CDC uses database triggers to capture changes as they occur. This method is easy to implement but can impact database performance.
- Timestamp-based CDC uses a timestamp column in the database to identify and capture changes since the last extraction. It is straightforward but may not capture all changes in real-time.
Once changes are detected, they are captured and prepared for streaming. This may involve data formatting and filtering out irrelevant changes. The captured changes are then streamed in real time to a target system, such as a data warehouse, analytics platform, or another database. This process ensures that the destination system is always up-to-date with the latest data changes, enabling real-time analysis and reporting.
For example, a retail company uses CDC to stream sales data from its transactional database to a real-time analytics platform. This lets the company monitor sales performance and inventory levels in real-time.
What is the impact of GenAI on Data Engineering?
Common challenges
Implementing a robust CDC solution requires careful planning and expertise. Ensuring that the streamed data remains consistent and accurate can be challenging, especially in distributed systems. Solutions include using reliable CDC tools and implementing strong data governance practices.
CDC can impact the performance of source systems, especially with trigger-based methods. Log-based CDC and other non-intrusive techniques can help mitigate this issue.
Data fabric and mesh
As data architectures evolve to meet the growing demands of AI and machine learning, organizations are adopting new approaches to manage and integrate data more efficiently. Two of the most prominent modern approaches are data fabric and data mesh, which offer unique advantages when dealing with complex data environments.
Data fabric
Data fabric architecture
Data fabric is a modern architecture that provides a unified data integration layer across different environments, such as on-premise systems, cloud infrastructure, and hybrid setups. Organizations can access data from multiple sources without physically moving it. Data fabric tools use data virtualization technology to work.
Data virtualization creates a virtual layer that sits on top of multiple data sources and abstracts underlying complexities so you can interact with data as if in a single repository. The technology uses metadata to understand data’s structure, relationships, and location across different sources. For example, metadata maps virtual views so users can query the virtual data layer using standard SQL or other query languages. The data virtualization engine translates these queries into appropriate calls to the underlying data sources, retrieves the data, and presents it to the user in a unified format.
Data federation
Data federation is a data virtualization technique that emphasizes querying data across distributed systems without moving the data. A federated query runs against multiple data sources simultaneously. The data federation engine decomposes the query into sub-queries and sends them to the relevant data sources. The results are then combined and presented to the user as a unified dataset.
For example, an organization with data stored in various departmental databases uses data federation to run cross-domain analytics, such as combining sales data from the CRM system with financial data from the ERP system.
Is your Data Integration strategy future-proof?
Use cases
Data fabric simplifies real-time access and centralizes data management. You can ensure that governance and security protocols are consistently applied across all data sources.
It enables analysts to generate reports that include data from different sources without complex ETL processes. For example, an organization with data spread across multiple technologies uses data virtualization to create a unified view for its business intelligence tools.
It also allows organizations to adapt to changing data requirements quickly. For example, a company undergoing a merger integrates data from the two merging entities using data virtualization. It supports business operations while the underlying data infrastructures are harmonized.
Data fabric is particularly beneficial for organizations adopting AI in multi-cloud or hybrid-cloud environments. It unifies access to data spread across a variety of platforms, including on-premise, cloud, and hybrid systems. By providing a seamless integration layer, data fabric ensures that AI-driven applications can access and analyze data in real time, regardless of where the data resides. This capability is crucial for AI model training and decision-making.
Potential limitations
While data fabric simplifies data access, setting up a data virtualization environment can be complex and requires careful planning, especially in environments with disparate data sources.
Depending on the complexity of queries and the performance of underlying data sources, it can sometimes result in slower response times than traditional data warehousing.
Data mesh
Data mesh promotes the idea of self-service data infrastructure, where teams can independently build, manage, and share their data systems without relying on a central data team. Instead of data flowing through a single, central system, every team manages and treats its own data as a product. Teams can manage their data autonomously while still adhering to the organization’s overarching governance and security standards.
This autonomy speeds up decision-making and fosters a more agile, data-driven environment. Organizations can scale more effectively.
Data mesh and data fabric are synergistic, not competing solutions. Read our detailed guide on data mesh vs. data fabric to learn more.
Data orchestration
As data systems become more complex, automating data flows is a necessity. Data orchestration came into play as a way to manage, coordinate, and automate the steps involved in moving and processing data across different systems. Instead of manually triggering data workflows, orchestration tools allow businesses to automate these processes, ensuring data pipelines run efficiently and smoothly.
Orchestrating data pipelines that include both batch processing and real-time streaming is increasingly crucial for AI-driven decision-making. By automating and managing these complex workflows, data orchestration ensures that AI models receive the most current data, whether through periodic batch updates or real-time streams. This capability is essential for businesses that rely on up-to-the-minute data for predictive analytics and AI applications, allowing them to make faster and more accurate decisions.
How data orchestration works
Data orchestration tools automate the execution of data pipelines, including data extraction, transformation, loading, and other processes. These workflows can be triggered based on specific events, schedules, or conditions. You also get monitoring and logging features to track the status of data workflows, detect issues, and ensure that data is processed correctly.
Mechanisms for error handling and recovery, ensuring that data processes can continue smoothly even in the event of failures or disruptions.
For example—a company uses data orchestration to automate the end-to-end ETL processes and manage batch and real-time data processing tasks.
Data integration tools
As data integration techniques evolved, different tools emerged to support individual techniques. For example:
- Informatica, Talend, and Microsoft SSIS for ETL
- Hightouch and Census for reverse ETL
- Snowflake, Google BigQuery, and Amazon Redshift as warehouses for ELT.
- Tools like dbt (data build tool) to manage and automate transformations within the data warehouse
- Debezium, Oracle GoldenGate for CDC
- Tools like Apigee, Mulesoft, and Zapier for API integration
- Denodo, IBM Cloud Pak for Data for data virtualization.
The tools represent a progression of different generations of data integration technology. First-generation ETL tools are gradually replaced by second-generation API tools, eventually replaced by third-generation ELT tools.
However, we are now in the fourth generation of data integration. Instead of a range of complex tools, you can use one tool that prepares data for analysis and manages data flow for tasks like ML/AI model training.
For example, Nexla uses a converged integration approach that combines ETL, ELT, data streaming, and API-based integration into a single design pattern. Organizations can manage all their data integration needs within a single platform, simplifying operations and reducing costs.
Nexla provides the data integration features your organization needs to be future-ready.
- Metadata-driven integration—Metadata provides critical information about data structures, relationships, and lineage, which Nexla uses to automate data discovery, mapping, and transformation.
- A comprehensive library of pre-built connectors so you can push and pull data between various systems.
- Virtual data products as an abstraction layer to simplify data integration from multiple sources into multiple destinations.
More importantly, you can use Nexla to quickly build no code/low code data pipelines from diverse data sources to vector databases for LLM fine-tuning and RAG workflows.
Talk to a data integration expert
Conclusion
Data integration is at the core of modern data-driven organizations. You want a solution that can meet the diverse data needs of different organizational units while still being centrally governed and managed. Tools like Nexla can advance your organization to the latest generation of data integration technology.
Nexla’s metadata-driven integration is crucial for automating AI model training and fine-tuning workflows. Additionally, Nexla’s comprehensive library of pre-built connectors enables organizations to seamlessly connect to a wide range of AI tools, vector databases, and machine learning platforms. This makes it easier to integrate data sources directly into AI workflows, fueling GenAI and predictive models with accurate and timely data.