
Data products key concepts
- Chapter 1: Data Engineering Best Practices
- Chapter 2: Data Pipeline Tools
- Chapter 3: Kafka for Data Integration
- Chapter 4: What is Data Ops?
- Chapter 5: Redshift vs Snowflake
- Chapter 6: AWS Glue vs. Apache Airflow
- Chapter 7: Data Mesh
- Chapter 8: Data Connectors
- Chapter 9: Data Management Best Practices
- Chapter 10: Automated Data Integration
- Chapter 11: Data products
- Chapter 12: Data Engineering Automation
In the most basic terms, data products are ready-to-use entities that process data and generate results. In a data-driven world where data is the new oil, data products serve as the refined fuel at the pump: meticulously defined, compliant with regulatory standards, and effortlessly accessible to consumers for diverse applications, be it in cars, trucks, or generators.
According to DJ Patil, former US Chief Data Scientist, a data product is “a product that facilitates an end goal through the use of data.” Building on this, we can define a data product as a trustworthy and ready-to-use collection of data, metadata, code, and policies that is comprehensible, coherent, and consistent. It is designed for a specific end goal and is easily discoverable and reusable.
Based on the definition above, is a spreadsheet, a data API, or a database table a data product? Not exactly: These are essential ingredients but not the product itself. Are data marts built on top of data warehouses considered data products? Somewhat, yes, as they are denormalized, aggregated, and refined views on raw data and can deliver value.
What is it, then, that makes a collection of data into an end-to-end, independent data product? Additional features, like metadata, discoverability, governance, and data quality, make the data product ready to use independently or even to be reused in derived data products. Data products can help organizations and their data teams advance quickly from data-in-use to ready-to-use.
In this article, we delve into the intriguing and evolving world of data products. We examine how these products revolutionize the way data-driven assets and insights are delivered and consumed. We explore the various types of data products and the key features that make them effective and take a closer look at their architecture and how they power broader ecosystems like data meshes. Finally, we discuss how to maximize value and speed up the time to value of data products.
Summary of key concepts about data products
| Concept | Description |
|---|---|
| What is a data product? | A data product is a trustworthy and ready-to-use collection of data, metadata, code, and policies that is comprehensible, coherent, and consistent. It is designed for a specific end goal and is easily discoverable and reusable. |
| Data product types | Data products can be categorized based on alignment or function. In terms of alignment, there are source-aligned, consumer-aligned, and aggregate data products. When it comes to function, data products can range from raw data to derived data products or data products supporting algorithms, decision-making, and automated decision-making. |
| Data product characteristics |
|
| Benefits of a data product |
|
| What does the data product enable? |
|
| How are data products created? | Data products are developed by collecting relevant data, performing data cleaning and transformation to ensure quality, integrating diverse data sources, analyzing and modeling the data to extract insights, optionally visualizing the findings, refining the products through feedback, and deploying them for end-users. The data fabric automates this process with metadata-driven intelligence, facilitating efficient and low/no-code data product development. User-defined data products allow for a customized approach, ensuring alignment with specific user requirements. |
| Examples of data products |
|
| Measures for data product success |
|
Data product categorization
One way of categorizing data products is based on the type of data they represent.
Source-aligned or raw data products
These products represent data with minimal transformation from its original form in the operational system. An example of this could be a table or view that mirrors the data present in an operational database.
Such data products can be entirely or largely autogenerated by leveraging metadata within the framework of a data fabric architecture. Nexla’s detected Nexsets can be used to create such data products by simply providing data credentials to the source, which then neatly organizes them with schemas, samples, descriptions, annotations, ratings, and more.
Consumer-aligned data products
This type of data product is designed to meet the needs of a specific consumer or group of consumers. An example could be a dashboard or report tailored to the needs of a specific department within an organization. Creating a consumer-aligned data product may require many steps, such as masking or hashing sensitive data, enriching data from external sources (e.g., converting from lat/long coordinate data to street addresses), and other operations that ultimately cause data to become consumer-aligned.
What is the impact of GenAI on Data Engineering?
Aggregate and derived data products
These data products encapsulate processed, transformed, and often aggregated information from raw data, which is used to drive overarching business metrics. For instance, a user-defined data product might be a transformed and rolled-up sales fact aggregate report. This could present monthly sales data across various regions and product lines, providing a comprehensive view of company sales performance for strategic decision-making. Nexla’s derived Nexset capability comes in handy for building such data products iteratively.
Nexla’s derived Nexsets are full-fledged derived data products and function the same way as any other Nexset. That means they can serve as an input to create more derived Nexsets, each with its own documentation, access control, etc. It’s as simple as adding a function to a series of Nexsets. Read more about all the capabilities of Nexsets here.

Data product lifecycle
The data pipeline lifecycle is helpful when designing data products of any type. It divides the design process into four major capabilities—data acquisition, storage, processing, and delivery—that have been illustrated in the figure below in the context of Nexla’s data product lifecycle. To read more on designing efficient data pipelines for data products, refer to this article on data engineering best practices.
Is your Data Integration ready to be Metadata-driven?
Data product characteristics
Let’s discuss the characteristics of a data product using the example of a customer churn prediction data product. This is a model that uses historical customer behavior and feedback data to predict which customers are likely to stop using a service or product. It can be used by various stakeholders within an organization for different purposes, such as marketing campaigns, retention strategies, or customer service improvements.
The model can be packaged as a data product that includes the following:
- Input data sources, such as transaction records
- Output predictions, such as churn scores
- The code or logic that generates the predictions, such as machine learning algorithms
- The metadata that describes the inputs and outputs, such as schema definitions
- The policies that govern the access and usage of the model, such as privacy regulations
- The quality metrics that monitor the performance of the model, such as accuracy or recall
If we overlay the characteristics of a data product to this customer churn example, we can check all boxes of a robust, reliable, and reusable data product.
Discoverability, addressability, and accessibility
A customer churn prediction model should be easily discoverable, addressable, and accessible by relevant teams within an organization. This can be achieved through the use of a data catalog or data product marketplace that allows teams to search for and access the model. Metadata for data products should be published for easy discovery and selection. This includes information such as security access rights, data creators, version numbers, purpose, and user consent. The model should have a unique identifier or URI that can be used to locate it. This information can be included in the metadata of the model for easy reference.
Nexla’s Data Product Marketplace does what’s described above, allowing users within an organization to easily discover, access, and share data products.
Trustworthiness
The customer churn prediction model should be reliable and accurate. This can be ensured through the use of data quality checks, service-level objectives (SLOs), data provenance and lineage tracking, and logic validation.
Self-describability
To make a customer churn prediction data product self-describing, it is important to incorporate well-defined data schemas with explicit semantics and syntax. This enables data consumers to independently access and utilize the data without requiring additional support. The inclusion of comprehensive metadata and schema semantics facilitates efficient data discovery and access by providing necessary contextual information.
Interoperability
The customer churn prediction model should be able to work with other systems and tools, such as CRM and marketing automation programs. This can be achieved through interfaces and APIs for integration with other systems while still maintaining governed data access.
Interoperability is a breeze with data products in Nexla because they come with hooks for delivery. Clicking the “Send” button in a Nexset allows users to choose the format and system in which they want the data delivered.
{kind=link}
Observability
Observability is an important DataOps component that enables the real-time monitoring and analysis of data pipelines and workflows. Providing a comprehensive view of the entire data journey from source to end-user allows for the rapid detection and resolution of issues. In the context of a customer churn prediction data product, this means that any problems with the data or model can be quickly identified and addressed to ensure accurate and reliable predictions. To see how Nexla’s data monitoring capabilities align with observability principles, refer here.
Guide to Metadata-Driven Integration
-
Learn how to overcome constraints in the evolving data integration landscape
-
Shift data architecture fundamentals to a metadata-driven design
-
Implement metadata in your data flows to deliver data at time-of-use
Security
Access to the customer churn prediction model should be controlled and monitored according to policies that govern its access and usage (such as privacy regulations). This can be achieved through data governance policies, role- or entity-based access control, and least privilege mechanisms.
Version control
Changes to the customer churn prediction model should be tracked and managed. This can be supported through continuous integration / continuous deployment (CI/CD) workflows for managing changes to the data product.
Other characteristics
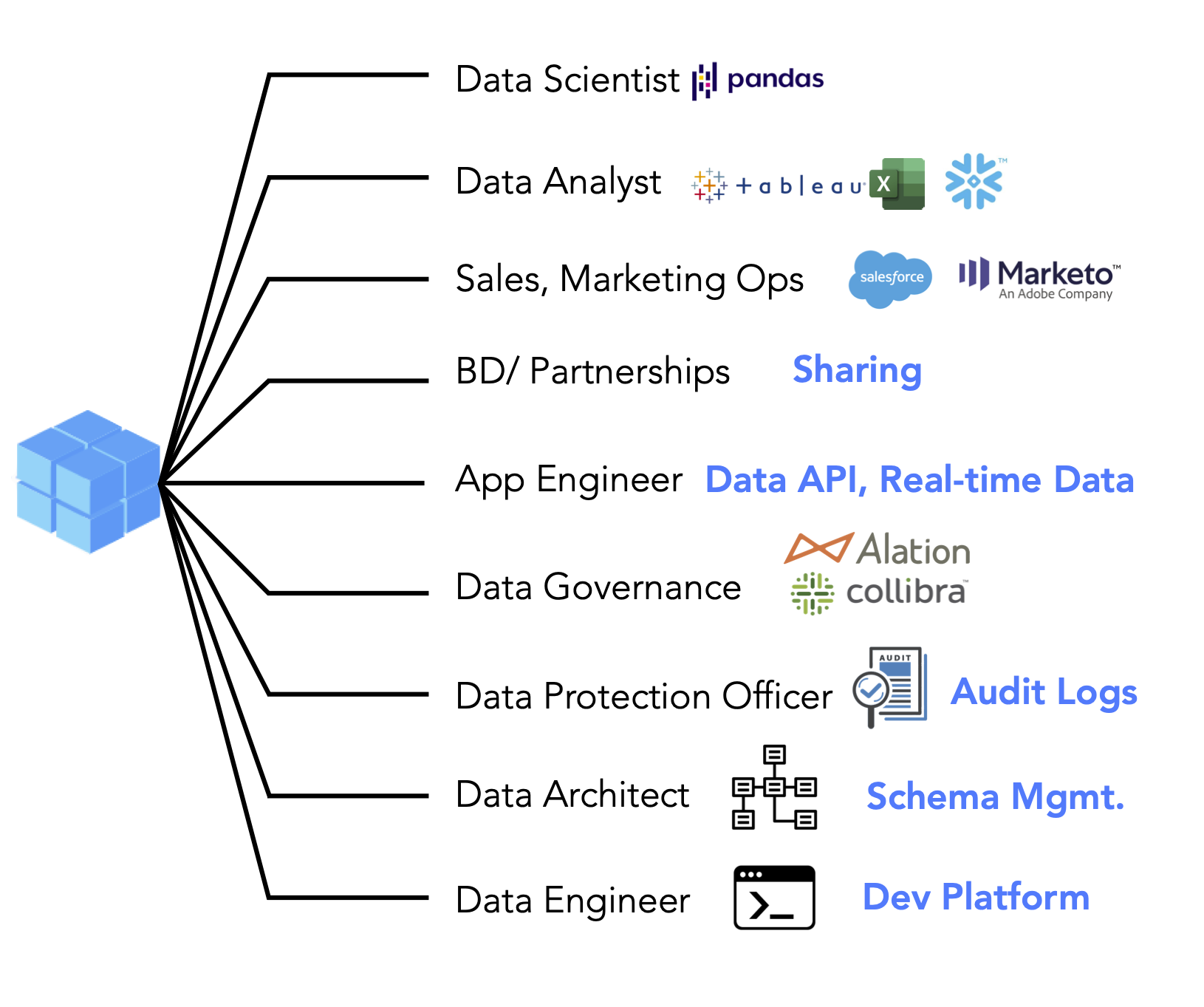
In addition to the characteristics described above, other important attributes of data products may include scalability (being able to handle large volumes of data efficiently), portability (the ability to move between different environments easily), and reusability (the capability of serving multiple purposes without significant modification). Nexla’s data products embody these characteristics, as can be seen in the figure below.
{kind=link}
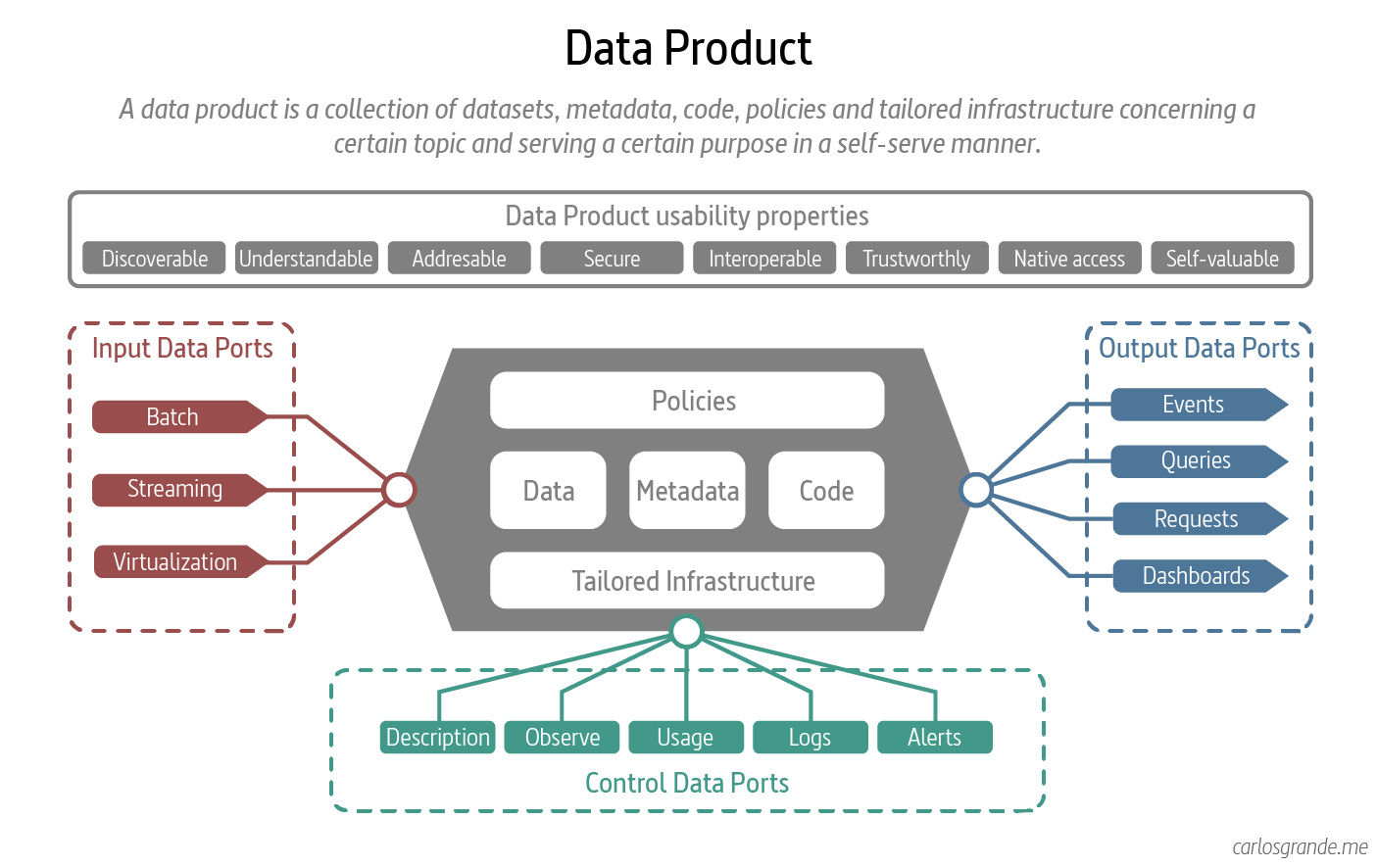
A data product is an architectural unit that can be deployed independently and has high functional cohesion. It contains all the necessary structural elements for its operation. Architecturally, a data product can be divided into four components:
- Core product: Consists of datasets, metadata, code, and policies related to a specific topic and supported by the platform. Independently, it has intrinsic value and can be reused across use cases.
- Input ports: Receive data that will constitute the data product. They define the format and protocol for reading data from operational source systems or other data products (internal or external).
- Control ports: Provide monitoring, logging, and metrics for managing and observing the data product. They also provide public and self-description information (ownership, organizational unit, license, version, etc.) accessible through the marketplace.
- Output ports: Define the format and consumption protocol for exposing data. This can include database tables, files, APIs, or reports, which can be accessed by final consumers or other data products.
A sample architecture of a data product has been illustrated below.
{kind=link}
Data products in a wider ecosystem: data meshes or data fabrics
In broader data architectures, such as data meshes and data fabrics, data products are essential for providing data as a fundamental design element. Within a data mesh structure, data products are the fundamental building block, where every node represents a data product that operates within its own defined context. This approach allows for data to be managed and delivered in the same manner as any other product within an organization, with an emphasis on applying product-oriented thinking to data.
Data products fit into domain-driven design by serving domain-oriented analytical data. For example, in a data mesh with artists, podcasts, and user domains, each domain could have its own set of data products tailored to meet its specific needs. These data products would be designed to provide relevant and actionable insights to support decision-making within each domain. The figure below illustrates the different domain data products in a music-industry-related data mesh design.
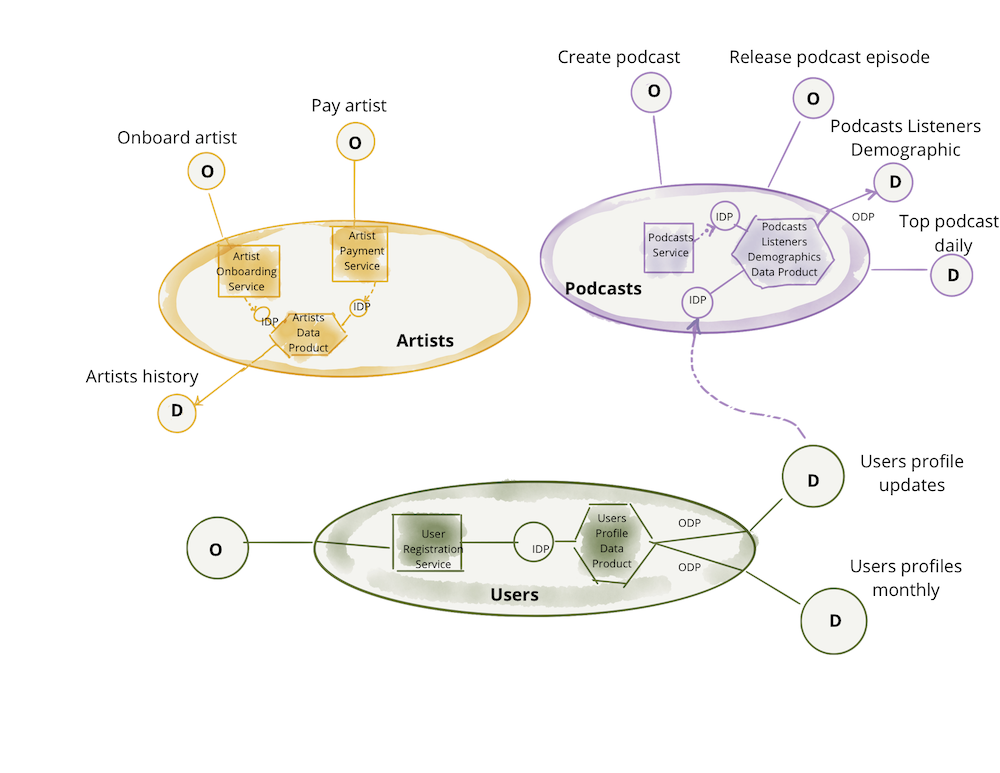{kind=link}
A metadata-augmented data fabric streamlines and automates the process of developing data products. By enhancing the data fabric with self-describing data products, it enriches the fabric with additional metadata, enabling the creation of derived and aggregated data products. The data fabric’s universal connector architecture and metadata intelligence layer form the fundamental components for low/no-code data product development, as illustrated in the figure below. One example of such metadata-augmented data products are Nexsets, which seamlessly integrate with a continuous-intelligence-based data fabric.
{kind=link}
Maximizing the value of data products
The following best practices and recommendations can be implemented to maximize the value of data products in a technical environment:
- Implement a fusion team model: Assemble a cross-functional data product team composed of members with diverse expertise, such as data scientists, engineers, designers, and business analysts, to collaborate on the design and delivery of data products.
- Utilize design or product thinking: Employ design thinking methodologies to gain a deep understanding of user needs and develop data products that effectively address those needs. Applying product thinking to the development of data products can help organizations shift their focus from project-based delivery to continuous value creation. This approach involves treating each domain’s dataset as an independent product with its own lifecycle and a dedicated team responsible for its development and maintenance.
- Encourage reusability: Data products need to be logical, i.e., every new data product shouldn’t create a new copy of data. Design data products with the intention of reuse to decrease development time and increase efficiency.
- Establish clear business objectives: Define specific business goals that inform the data strategy to ensure effective utilization of data. Leverage data mesh or data fabric paradigms to accelerate enterprise-wide adoption of data products.
- Standardize the process of data product development: Standardization and template-driven design are key to ensuring consistency in data product development. Leverage a minimum viable data product checklist and utilize knowledge sharing to iterate and enhance the product development life cycle.
- Make use of metadata management, data product catalogs, and DataOps: These are key to data product success and widespread adoption.
- Democratize data products: Empower anyone to get started with data product development with tools like Nexla.
Empowering Data Engineering Teams
| Platform | Data Extraction | Data Warehousing | No-Code Automation | Auto-Generated Connectors | Metadata-driven | Multi-Speed Data Integration |
|---|---|---|---|---|---|---|
| Informatica | + | + | - | - | - | - |
| Fivetran | + | + | + | - | - | - |
| Nexla | + | + | + | + | + | + |
Conclusion
Data products are revolutionizing how ready-to-use data is provided to a wider audience and can accelerate value generation, reusability, and overall ROI for organizations. Be it in a data mesh, data fabric, or standalone, a data product has technical and infrastructure dependencies, which makes it important to consider the platform and technologies when defining the scope of a data product. The ultimate goal of a data product, though, is to bridge the gap between data and its consumers. Its value is determined not merely by the content but also by how it is received by its intended audience. As Steve Jobs once said: “You’ve got to start with the customer experience and work back toward the technology—not the other way around.”